Giới thiệu
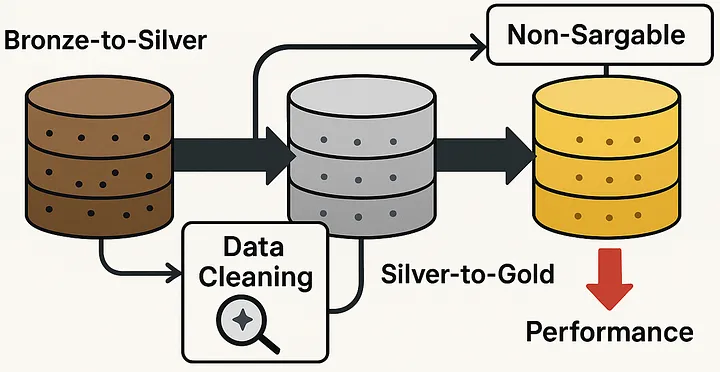
Nếu bạn từng làm việc với data lakehouse, chắc chắn bạn biết chuyện: dọn dẹp dữ liệu luôn là bước không thể thiếu, thường được thực hiện khi chuyển dữ liệu từ Bronze lên Silver. Thông thường, mọi người tập trung vào việc loại bỏ dữ liệu trùng lặp hoặc xử lý giá trị bị thiếu.
Nhưng có một lỗi phổ biến — hay bị bỏ qua — lại gây ra tác động lớn đến hiệu suất và chi phí, đặc biệt nếu bạn chỉ phát hiện và sửa nó ở giai đoạn Silver-to-Gold, như nhiều người vẫn làm.
Vấn đề là gì?
Vấn đề xảy ra khi dữ liệu của bạn — đặc biệt là ở một số cột quan trọng — không được định dạng đúng ngay từ đầu. Thay vì xử lý sớm, bạn lại để yên đến khi viết truy vấn ở giai đoạn Silver-to-Gold, và phải “chữa cháy” bằng cách dùng hàm trong điều kiện lọc.
Ví dụ kinh điển: GUID (Global Unique Identifier).
GUID có thể viết hoa hoặc viết thường, tùy vào hệ thống gốc khi ingest dữ liệu. Nhiều người xử lý chuyện này bằng cách dùng lower() hoặc upper() trong câu lệnh lọc, đại loại như:
WHERE lower(guid_column) = 'abc123...'
Nghe có vẻ đơn giản, nhưng hậu quả thì không hề nhỏ.
Câu chuyện thực tế
Mình đã thử nghiệm setup một star schema với 3 loại khóa khác nhau: integer, GUID và SHA256. Dữ liệu mô phỏng bao gồm:
| Bảng | Số dòng | Cột |
|---|---|---|
| dim_customers | 100.000 | dim_id, dim_type, name, age, gender, city |
| dim_products | 10.000 | dim_id, dim_type, name, category, color, size |
| dim_locations | 100 | dim_id, dim_type, country, state, city |
| fact_sales | 36,5 triệu | product_dim_id, customer_dim_id, location_dim_id, date, quantity, price |
Chạy truy vấn trên cluster tầm trung của Microsoft Fabric, với dữ liệu GUID sạch sẽ (đã viết thường sẵn), thời gian xử lý chỉ hơn 25 giây.
Nhưng nếu bạn thêm lower() vào điều kiện lọc, ngay cả khi GUID đã viết thường từ đầu, thời gian bỗng nhảy vọt thêm khoảng 14.5 giây.
Nếu hệ thống phức tạp hơn, dữ liệu lớn hơn, số giây này sẽ biến thành số phút, số giờ — và số tiền.
Nguyên nhân sâu xa: “Non-sargable queries”
Vấn đề này có tên gọi kỹ thuật là non-sargable query. Khi bạn viết điều kiện lọc có chứa hàm, như lower(), upper(), trim()… thì database sẽ mất khả năng tối ưu hoá truy vấn bằng index. Lý do? Vì hệ thống buộc phải tính toán giá trị từng dòng rồi mới so sánh, thay vì dùng chỉ mục để tìm nhanh.
Ví dụ đơn giản:
sql
-- Tệ: Không thể tận dụng index
SELECT Id, Name FROM Persons WHERE Id + 1 = 2— Tốt: Sử dụng index được
SELECT Id, Name FROM Persons WHERE Id = 1
Việc dùng hàm trên cột dữ liệu giống như yêu cầu database phải “tính toán mọi trường hợp có thể” thay vì nhảy thẳng đến kết quả, và đó là nguyên nhân khiến hiệu suất giảm thê thảm.
Giải pháp
Thiết lập quy tắc định dạng dữ liệu ngay từ sớm.
-
Quy định rõ: GUID luôn phải viết thường (hoặc viết hoa), enums viết hoa, số thập phân có bao nhiêu chữ số sau dấu phẩy.
-
Thực thi quy tắc này từ bước Bronze-to-Silver, khi dữ liệu mới vào hệ thống.
-
Hạn chế tối đa việc dùng hàm xử lý dữ liệu trong câu lệnh truy vấn ở Silver-to-Gold.
Kết luận
Trong thế giới dữ liệu, thời gian chính là tiền bạc.
Việc xử lý dữ liệu càng sớm, càng triệt để ở giai đoạn Bronze-to-Silver sẽ giúp bạn tiết kiệm được công sức, chi phí và rất nhiều thời gian ở các bước sau.
Vậy nên, đừng để những lỗi nhỏ như định dạng cột kéo tụt hiệu suất của hệ thống bạn xuống đáy. Hãy chuẩn hóa sớm, xử lý sớm và viết truy vấn thật “sạch”!
Nguồn: https://christianhenrikreich.medium.com/lakehousing-removing-one-of-the-biggest-performance-killers-in-bronze-to-silver-processing-8ed4ce372de6
